
Testing with Test Doubles?
Dummy, Stub, Spy, Mock or Fake
Found a typo? Edit me
Test Doubles
A Test Double is an object that can stand-in for a real object in a test, similar to how a stunt double stands in for an actor in a movie.
As I wrote in “The importance of the Tests in our Software”, there are several types of tests. They are also known as Test Doubles instead of “Mocks”.
The five types of Test Doubles are:
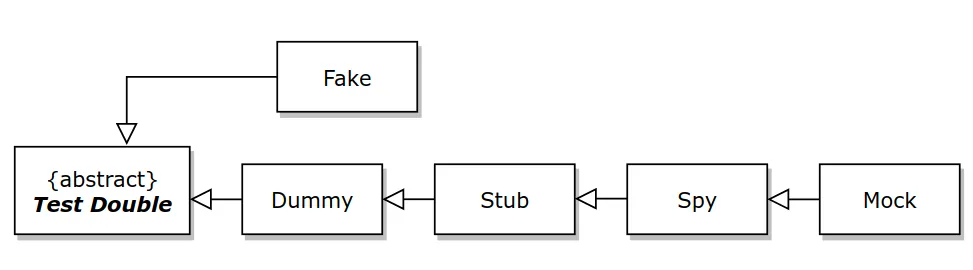
- Dummy: It is used as a placeholder when an argument needs to be filled in.
- Stub: It provides fake data to the SUT (System Under Test).
- Spy: It records information about how the class is being used.
- Mock: It defines an expectation of how it will be used. It will cause failure if the expectation isn’t met.
- Fake: It is an actual implementation of the contract but is unsuitable for production.

The snippets are a pseudo-language based on a mix of PHP & Java.
The idea is to make it understandable to everyone familiar with OOP.
Dummy
The dummies are objects that our SUT depends on, but they are never used. We don’t care about them because they are irrelevant to the test scope.
Let’s imagine we have a service with a dependency that is irrelevant in the current test. We can perform something similar to the following snippet:
Stub
A stub is an object which returns fake data.
Let’s imagine our service depends on a user model, then the service does something, and finally, it returns the user’s UUID. We can create a stub object with fake values to assert the service works as expected.
To test this service, we can create a stub of the user and check if the response is what we were expecting.
Spy
A test spy is an object capable of capturing indirect output and providing indirect input as needed. The indirect output is something we cannot directly observe.
We can achieve that by extending the original class and saving the function params as class arguments.
In the following snippet, we can know exactly how many times the log() method has been called, as well as the content of the messages. The point of this spy is to have much more knowledge of the internal object state in exchange for deeper coupling, which could be problematic in the future because it makes our tests more fragile.
The following would be the implementation of the spy in a test:
Mock
A mock is an object that is capable of controlling both indirect input and output, and it has a mechanism for automatic assertion of expectations and results.
Imagine the ShoppingCart class calls the database and performs big and complex functions. For this reason, we cannot unit test this class correctly due to the coupling.
In this kind of situations, mocking is the best option if we cannot modify this class easily (maybe the class is used in different parts), and it could take too long to refactorize.
My favourite solution for this is “extract method refactoring”:
And this is the mock:
This methodology is very handy when we want to refactor a class step-by-step, but we could go further and extract that logic in a new class, then when the class
ShoppingServiceis created, just injecting the dependency via constructor would help us to separate the logic.
Fake
A fake is a simpler implementation of real objects.
Fakes are used when we want to test an infrastructural class, in other words, fakes are for the classes which are beyond our application limit (repositories or queues, for example).
As you can observe in the first picture (the diagram), a fake is not in the hierarchical line within the dummy, stub, spy or mock. This is because a fake can behave like a dummy, stub, spy or mock for our concrete use case.
So, when we use this fake repository, we will receive a stub User.
Final thoughts
We must know the scope of the code we are going to test to get coupled as less as possible. That means if we have to pick a test double, first, we must know if the test is within our boundaries or not, if not, a fake is the best option, otherwise, my recommendation is to pick the corresponding test with the least knowledge as possible: dummy, stub, spy or mock (in that order).